95% Less Real Data, Better Performance on Biomedical Reasoning
With only 10K failure mode-targeted synthetic examples, TinyLlama (1.1 B) beats GPT‑4o mini and an equal‑sized real‑data set on PubMedQA. We show that the right data matters more for performance than data volume or human quality.
Introduction
Biomedical question answering (QA) demands deep domain expertise and vast annotated datasets by domain experts. PubMedQA—a benchmark of yes/no/maybe questions drawn from medical abstracts—poses a steep barrier: collecting and verifying hundreds of thousands of expert‑curated examples is costly, time‑consuming, and often infeasible.
Key question:
Can we replace bulk real‑data collection with a smart, error‑driven synthetic pipeline to achieve equal or better performance—using a tiny fraction of the dataset?
Strategy to get the most performance per sample
Sample Efficiency Mindset: Focus on impact per example, not dataset scale—aim to close the biggest performance gaps with as few samples as possible.
Performance-weighted data curation and design: Deploy our Phinity LLM engineering agents to inspect TinyLlama’s outputs on the validation PubMedQA set, automatically surface and rank high‑impact error modes, and design the optimal dataset coverage to maximize performance given a sample budget.
Targeted synthetic data generation: Construct a synthetic data pipeline with medical rules and verification methods. Generate diverse synthetic data to target the error modes.
Fine-tune and Evaluate: Evaluate base and fine-tuned models on held-out test set
Experimental setup
We fine-tuned a 1.1B TinyLlama model across four conditions:
10k PubMedQA Train: 10K QA pairs constructed from scraped real PubMed abstracts (the “real‑data” control).
10k Evol-Instruct: 10K examples generated via the industry‑standard synthetic data generation method(WizardLM’s Evol-Instruct), widely used in research labs to generate diverse synthetic data for post-training frontier LLMs, with 500 scraped PubMed abstracts as seed.
10k Phinity: Error-targeted curated synthetic data with performance-efficient coverage design, with 500 scraped PubMed abstracts as seed.
Results
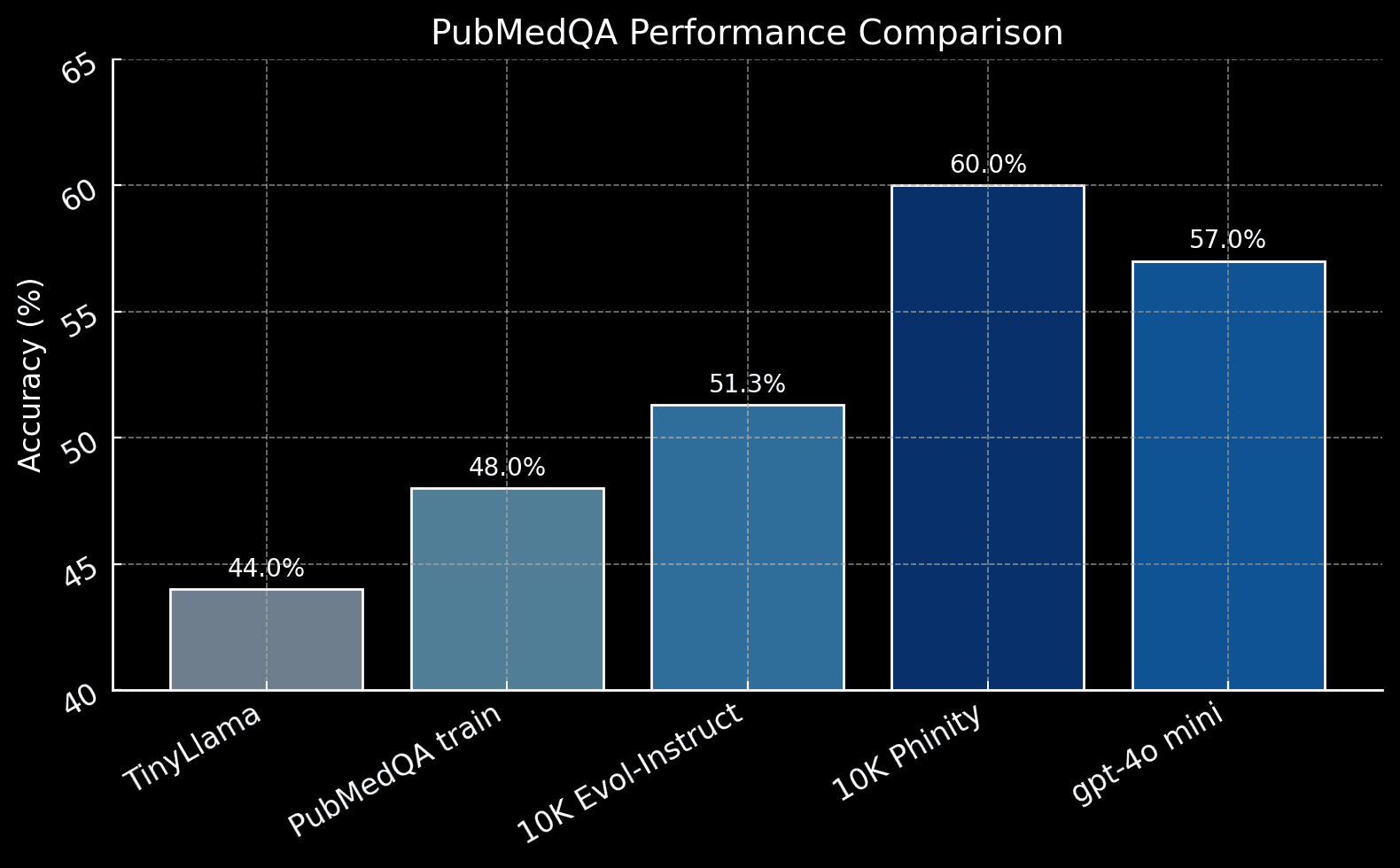
Across our five evaluation conditions, fine‑tuning TinyLlama (1.1 B) on targeted synthetic data yields the highest PubMedQA accuracy, outperforming both real‑data and closed‑model baselines:
Model | Accuracy |
|---|---|
TinyLlama (base) | 44% |
Real data baseline (TinyLlama trained on 10k PubMedQA Train) | 48% |
Synthetic data baseline (TinyLlama trained on 10k Evol-Instruct) | 51.3% |
Phinity (TinyLlama trained on 10k Phinity) | 60% |
GPT-4o mini | 57% |
Key takeaways
Right data beats real data: Our results support that precisely engineered, coverage-optimized synthetic data delivers over twice the impact per sample compared to real or unconstrained synthetic data generation methods.
Synthetic data can be performant, if done correctly: It is possible for synthetic data to be performant if filtered for quality, diversity, and training signal. Generating and validating a few thousand synthetic examples takes hours and minimal expert time—versus months and high cost for human annotations.
LLM development can be systematic like debugging software to get results - We treat LLM fine‑tuning like code debugging:
Identify high‑impact failure modes via error analysis
Generate minimal “patch” datasets to fix each error
Train, evaluate, and iterate
This approach is used in research and also to improve performance on task-specific LLM applications, where data is scarce and performance is critical.